Data science
As a data scientist, my job is to take data, clean it, analyze it, and use it to generate recommendations, forecasts, or other actionable insights that other people can use. I don't just make pretty plots, reports and dashboards all day though. You can divide analytics into three disciplines: descriptive, predictive, and prescriptive. Descriptive analytics is analyzing what happened in the past, and using that to create plots/reports/dashboards. Predictive analytics is using past data to try and (a) predict what will happen in the future, or (b) infer some information from incomplete knowledge (like "I predict that this image is a picture of a cat"). Prescriptive analytics builds off the results of descriptive and predictive analytics efforts to use the data that we have now to suggest the optimal course of action to take in order to induce the best outcome. My professional work involves a tiny bit of descriptive (mostly ad-hoc requests and making plots to show during meetings), but mostly predictive and prescriptive analytics, which can be truly impactful for the business.
Operations Research
I have used statistical and machine learning methods to do things such as match delivery drivers with orders, forecast which customers will place orders in the coming days, what delivery routes will look like tomorrow, determine the optimal sequence of orders to deliver, suggest optimal days to schedule inbound vendor deliveries, and cluster similar products to improve our demand forecast accuracy. As you can see, the general theme of my work is in supply chain operations, and involves a good deal of operations research, which I enjoy very much, because the mathematical tools used are significantly different from those I used to use as a physicist, so I get to learn new things all the time.
Optimizing matches between delivery drivers and orders
At Shipt, I am part of the "offering" squad, whose goal is to match our shoppers/drivers and orders in the marketplace. There are a number of different things to take into account when doing this matching, such as how likely it is that a shopper would want to take any specific order, the size of the order, how much time there is until the order is considered late, the supply and demand of labor in the market, etc. There are likely many different approaches, but our team is currently working on a generally applicable recipe:
- Look at every possible pair of (shopper, order) in the marketplace and estimate how "good" of a match they are, where "goodness" is determined by the probabilities that a shopper will claim an order and deliver it successfully
- Use these probabilities in an optimization step which seeks to maximize both shopper overall satisfaction with their match, and profits for Shipt
This involves a good deal of machine learning to predict match affinities, which are hyper-personalized so that we can really distinguish between individual shoppers. We also work on some interesting optimization methods, which span integer linear programming problems to Markov decision processes.
Routing optimization on demand
After gaining some familiarity with vehicle routing optimization from my work at ATD, I decided to build my own hobby route optimization service using the skills I had learned. It is composed of three microservices:
- The Valhalla routing engine for measuring driving distances/times
- A backend API which performs the routing optimization (built with OR-Tools and FastAPI)
- A frontend web application for allowing a user to manage their own vehicle routes using a simple point and click interface (using TypeScript, FastAPI, leaflet.js and the Fetch API)
All services are hosted on GCP, with the latter two using a serverless architecture (Cloud Run) deployed simply by pushing Docker images to the cloud. The architecture was particularly chosen so that the whole thing could scale according to load, and will run entierly for free with moderate use (using GCP's free tier of cloud compute), which I am especially proud of! My code is in a private repo for now because I am considering making this into a business, but I may open source it later.
Predictive routing and scheduling deliveries
In 2019, ATD began a new line of business doing 3PL (3rd-Party Logistics) for various tire manufacturers. Part of our agreements was that we would have until the end of the week to deliver orders to our retail customers, though we could deliver at any point before that if we wanted. I found that this flexibility could be exploited to choose the best day on which to deliver the order, so that the truck would have to make as minimal of a detour as possible to get to the customer. Using a statistical analysis of customer ordering patterns and Monte Carlo simulation, I could draw samples from the distribution of customers that order on any given future day, then simply connect the dots to make a route (ATD was using static routing at this point, so going from stops -> routes was trivial). Because of the randomness of the MC simulation, this effectively becomes a probabilistic forecast of delivery routes. It is then a simple matter to calculate the incremental cost incurred by adding a customer to this sample stop. Using this machinery, you can construct an MDP (Markov Decision Process) to determine the value function \(Q(s,a)\) (where the state \(s\) is the current set of customers + the time left to deliver, and the action \(a\) is the choice to deliver or not). This MDP can be solved using stochastic dynamic programming to yield a recommendation to either deliver now or wait until the next day and re-evaluate the situation. Currently, the algorithm runs on an hourly basis, generating recommendations for roughly 140 warehouses nationwide, and in a recent evaluation, shows an estimated savings of about $0.50/delivery on average.
Dynamic Routing at ATD
After learning that ATD's delivery routes were all static, I decided to investigate whether using a route optimization tool would be effective in reducing the cost of operating routes. Using Google's open-source constraint satisfaction solver OR-Tools, I devised a simple algorithm to solve the CVRPTW (Capacitated Vehicle Routing Problem with Time Windows), along with a couple other business-specific constraints, and simulated how the algorithm would perform by passing it sets of customer locations we had delivered to in the past. Our routing process at the time had only a vague notion of time windows (e.g. big customers were delivered to first so we could ensure consistency), so I figured out the "typical" delivery time of our customer, and assigned windows centered on that time, but of varying widths based on how frequently they ordered, how big of a customer they were, etc. What I found was that algorithmic routing could reduce the miles driven and time taken by 5-30% (depending on generous you were with time windows), and even reduce the number of vehicles needed altogether. These encouraging results convinced senior leadership to start searching for an enterprise solution for managing deliveries capable of dynamic routing, and at present, we are in the process of integrating one such solution into our supply chain systems. Another side effect of this work was that it started a serious conversation around customer service levels and delivery consistency, which had not been formalized in any way before. Work is currently underway to establish tiered customer service levels, which will each come with their own time windows, and I am providing advice and analysis on this front.
Even though ATD decided to go with a more complete enterprise solution for dynamic routing, I learned a great deal from the project, and decided to make my own web application capable of solving the CVRPTW to demonstrate this knowledge.
Machine learning side projects
Part of a data scientist's job is being able to use machine learning to extract insights from data.
In a nutshell, machine learning is a set of techniques for getting a computer to complete tasks without telling it explicitly what to do.
While there is immense practical value in using ML methods to solve business problems, I am also incredibly interested in it from a mathematical perspective.
There is a lot of beautiful theory that goes into making these algorithms that a lot of practitioners ignore because either it is too difficult to understand, or someone has made a scikit-learn estimator that turns it into a black box so you don't need to understand to get the job done.
Below is a sample of some of the machine-learning projects that I have worked on. If it's something I've done for fun or my own personal study, I'll have a link to the project. If not, it's probably something I've done for my employer, and I don't think they'd appreciate if I shared proprietary code.
Supervised
Supervised learning describes algorithms that learn tasks by example. You show a machine how something should be done, and it will try to learn a way to minimize the error between the way it does things, and the "right way" to do things. This can include classification, regression, and forecasting. A simple mathematical way of looking at it is that if you have a ground truth answer \(y\) which is determined by some data \(x\), a supervised learning algorithm tries to learn the function \(f(x;\theta) \approx y\), where \(\theta\) are the parameters of the algorithm.
- Spam classification in text messages
- Used natural language processing to classify text messages as either spam or "ham" (i.e. not spam) using a variety of ML techniques. Analyzed risk/reward trade-off of false positives/negatives.
- CO2 level forecasting
- Used data from the Mauna Loa observatory in Hawaii in order to forecast \(CO_2\) concentration levels and investigate periodicity. Big surprise - global warming is causing \(CO_2\) to increase rapidly, and unfortunately the rate is increasing.
- Pixel-wise classification of microscopy images
- Part of the 2017 Kaggle Data Science Bowl. The goal was to perform image segmentation by overlaying a mask on top of cellular nuclei to help researchers interpret the images in order to speed up biomedical research. I used a special type of convolutional neural network called a "U-Net" which is able to make accurate predictions at the pixel level.

- Handwritten digit classification
- Used a Residual Network (ResNet) to classify handwritten digits from the MNIST database.
- Iris classification and Titanic survivor prediction
- Two exercises that are well-suited to simple classification algorithms. Basically the "hello world" of machine learning.
Unsupervised
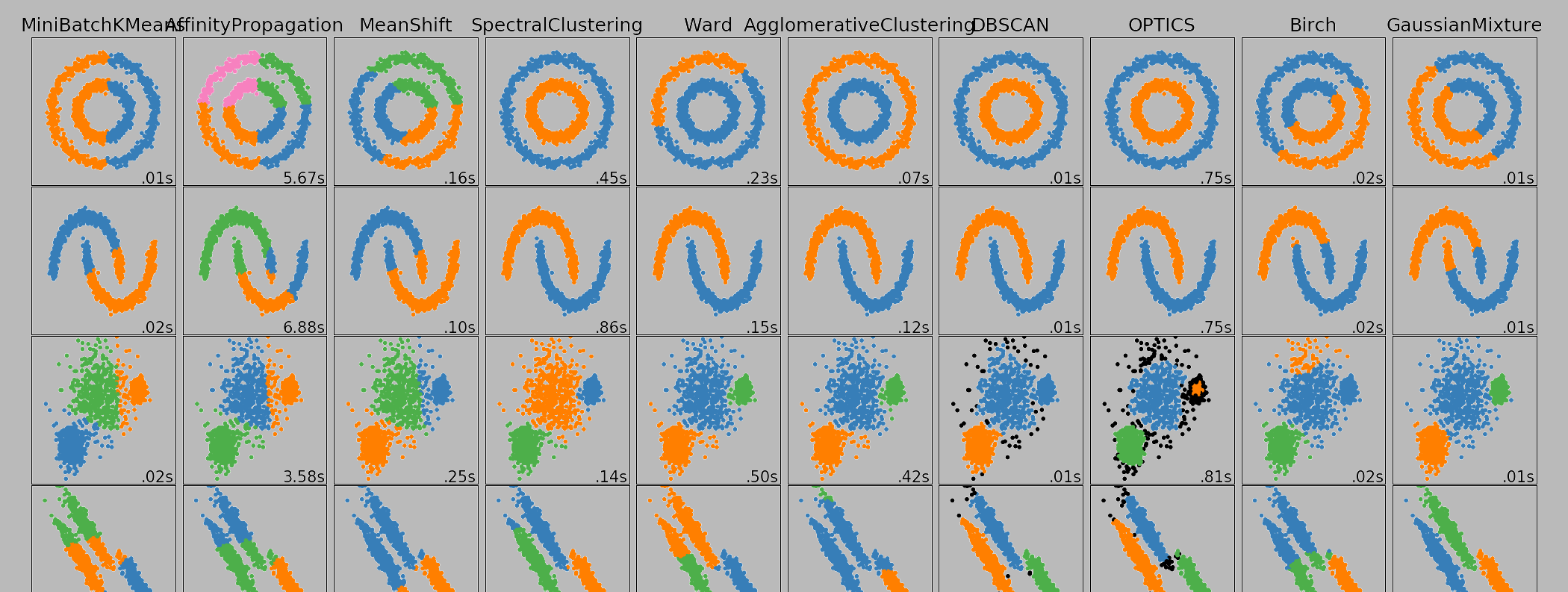
Unsupervised learning describes algorithms that can extract patterns from data without being told explicitly what to do. This includes clustering (like what's pictured in the banner image at the top of the page), dimensional reduction, autoencoders, etc. The set of tasks that unsupervised learning can solve are much more varied, though less well-defined than those of supervised methods, since there is no known "right answer".
- Product demand time series clustering
- At ATD, our forecasting software takes in a set of "seasonality groups", which are clusters of products that have similar seasonal demand patterns. Before I started there, this process was done manually; after applying unsupervised clustering techniques, I was able to both automate the process and improve the clusters significantly.
- Convolutional autoencoder (CAE)
- Used a convolutional neural network to compress and reconstruct images of handwritten digits from the MNIST database.
Reinforcement learning
Reinforcement learning is a more general paradigm where a machine learns to complete a task through trial and error. Unlike supervised learning, where there is a "correct" answer the algorithm tries to achieve given an input, a reinforcement learning agent (1) tries to maximize a "reward" which is given for accomplishing a task, and (2) learns an optimal sequence of actions rather than just a single prediction. This branch of machine learning is based on a statistical framework for optimizing sequential decisions called Markov Decision Processes (MDP).
- Determining optimal delivery times for customers with flexible delivery dates
- An idea I came up with at ATD; we have a set of customers who are flexible about the day they receive their orders on, and it may not be cost effective to deliver to a customer unless there are other customers nearby. So I devised an algorithm that uses MDP's to calculate the expected value of delaying the decision to ship the order, then compares with the current estimate to ship, and chooses the lowest-cost action.
- Sutton & Barto exercises
- While teaching myself the foundations of reinforcement learning, I studied from and completed exercises from this excellent textbook.
- Learning to play Pong
- Trained a reinforcement learning agent to play the game of Pong using a Deep Q-Network, using nothing but the raw pixels from the game screen as input. After 6 days of training on a GPU (2500 simulated games, 3.5 million frames), the RL agent (green, right) finally was able to outperform the built-in, pre-programmed opponent (orange, left).
Other
I've done some other minor machine learning work, like playing around with various neural network architectures, writing my own optimization algorithms, etc. These are all either works in progress, things that didn't work but were still interesting, and other miscellaneous things.
- Inception ResNet implementation
- Standalone script for generating ResNets with Inception blocks with TensorFlow (probably outdated since the release of TF 2.0)
- Deep learning presentation for statistics class
- Deep Convexity Annealing
- Experimental optimization algorithm that uses ideas from graduated optimization to train neural networks
- Multidimensional Bisection